Mitigating a DDoS, or: how I learned to stop worrying and love the CDN
TLDR:
This will mainly be a story into how I experienced and reacted to my first real-time attack. As you may or may not know, I did work in security for a few years prior to writing this post, so I wasn't entirely in the dark about what I could expect to see. However I had never experienced anything that I was personally responsible for being attacked.
So let's set the scene. I run a node of the "fediverse", a collection of servers that act as a social network without any central authority. It's all very cool and I recommend reading more on it if you have the time. It's a pretty nice way to get out of the shouty hellhole that is twitter. But anyhow, what it is isn't important right now.
What's important is that there was a user who I banned after breaking rules, and he got rather frustrated with that decision. After multiple attempts to ban-evade, he took it on himself to make sure that none of us could access the service either.
Now, I had set up my service rather naively, assuming good faith from other instance administrators and from users. I had no systems in place to mitigate an attack should one happen. And for about a year, no attacks came. So I never questioned it. That being said, I did have monitoring services in place from some weekend that I must have been exceptionally bored during. So I at least had nginx monitoring being piped into grafana.
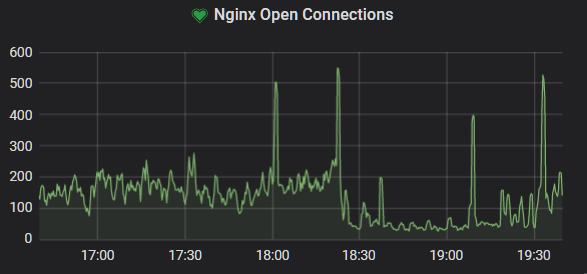
Dawn of the first day
Then it happened. Suddenly I was getting 502 errors, which was incredibly unusual. "Let's SSH in and find out what's broken" I thought. SSH didn't work.
"That's weird" I thought. "Why shouldn't I be able to SSH in? Maybe the
VPS died or there are network issues within scaleway?". So I log into the
scaleway web dashboard and find that they have no issues, and my VPS is running
without issue. Luckily they have a web-based terminal which I think is just
a serial connection to the host. So I use that to find out what the heck is
going on. Nginx logs show thousands of identical requests for the URL pattern
https://mysite.com/?<RANDOM_INTEGER>. A quick googling of the IP addresses in
use showed that they were tor exit nodes, and hence any attempt at an IP-based
rate limit would be in vain. Viewing nginx's error logs also showed that it was
having its socket pool exhausted, leading to the 502's i was seeing earlier.
So I was holding up to the stress, just nginx was failing to deal with it.
Some frantic googling later showed that I was probably being hit by slowloris, which keeps connections open for a long time, thus exhausting nginx's pool.
Good, a known threat. I can deal with that. I found this article which described how to mitigate the attack with nginx. After making the configuration changes specified, we were back online! Great.
Whilst I had some uptime, I set up OSSec to attempt to auto-ban any IPs spamming me too hard, and set up alerting on grafana to tell me immediately if the number of open connections to nginx ever rose above 1000.
Night of the first day
Pretty soon after I'd mitigated the first attack, I started getting 502 errors again. "what is it now?" I thought. Same SSH issues as before. The intensity of the attack had grown such that the network interface on the VPS was being overwhelmed to the point where it could accept no more connections. Which was just great.
My first thought was to put a load balancer in front of the VPS, which should theoretically be set up for precisely this sort of situation. Much playing with scaleway later it worked. Mostly. Scaleway's load balancers don't allow websockets, and websockets are used quite heavily in most frontend programs that use pleroma. Fantastic. So I can't do that.
Then I just thought "let's block all tor exit nodes with IPtables". So I did. It didn't work. Even if I dropped the connections at the door, there were just too many, and the NIC wasn't able to keep up.
So I thought the unthinkable. "Let's use a service explicitly set up to deal with this sort of attack". Cloudflare is pretty frowned upon within the fediverse userbase, for good reason. It's a bit of a hecking mess for anyone privacy-minded, especially with its SSL-stripping between host and client. But what other choice did I have at this point?
(Early) Dawn of the second day
By this point I was well and truly ill. It was well past midnight, I felt like collapsing. But I must remain strong. I must protect my sad weebs, and their place to vent and stay sane. Nothing is more important than that.
Much messing with DNS later and we're behind cloudflare. All connections are behind filtered at the door, and I can block tor without the connections ever reaching my NIC. I apologised to the 1 fediverse instance I knew of that used tor and watched as my service came back online. It wasn't perfect, but it'd do.
Cloudflare was actually a little... over-zealous in its blocking and had a tendency to reject legitimate fediverse server-to-server packets due to their unusual hosting location or content. This should have been expected, as the fediverse is at least partially made of people not allowed on more mainstream networks.
So I had to add a rule to allow legitimate connections through. I will not expand on how I did this here at risk of allowing someone to abuse it.
But we were online.
I went to bed, to collapse and try to recover
BZZT BZZT
My phone buzzes next to my ear. That's quite a rare thing for me. I check it like an idiot.
from: grafana subject: [Alerting] Nginx Open Connections alert
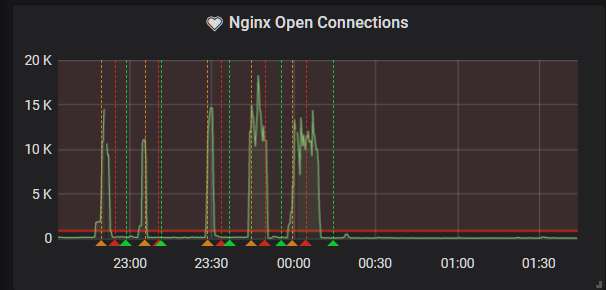
Oh great.
I decided to take the hit and enable URL rate limiting. This would cost me, but luckily cloudflare only charge for legitimate requests that don't get rate limited. Guess that makes sense. And I was ill enough to not care.
BZZT BZZT
from: grafana subject: [OK] Nginx Open Connections alert
There we go. Time to sleep.
Interlude
Some other things I learnt when setting all of this up:
- 1000 connections to nginx is not enough. One lain reply will instantly trigger this rule. Joys of being popular, eh? Use "an average of 1000 in any 5 minute period" instead.
- Cloudflare logs really suck for non-enterprise customers. I mean sure they tell you the times your firewall rules got triggered, but it's not easily exportable at all. This makes reporting malicious activity to hosting providers very hard if not impossible.
- If you use XMPP, the
_xmpp_serverSRV record is very useful. If you ever find yourself in this situation, offload your XMPP server to another VPS. A tiny one. Then use a SRV record to allow connectivity. Do not under ANY circumstances use this record to point to your main server, or the attacker will just read that and direct his attack there. All of your mitigation will have been pointless. - If you do make the mistake above, and are using one of the main cloud providers, you can just take an image of your hard drive and allocate a new instance, entirely separate from your original. You'll have some downtime, but you'll be on a theoretically unguessable IP address, hidden behind cloudflare.
- DO use the abuse addresses from any cloud providers used in the attack. They're usually quite responsive. AWS even has automatic-IP-scraping to try and auto-resolve any dispute. It doesn't work but hey, they have it.
(Dawn|Night) of the \d+th day
This pattern of "DoS attempt on a weekend" repeated a lot. Nothing really happened. The attack size was slowly ramping up, but nothing to be alarmed with. Downtime was minimal-to-nonexistent, depending on how quick I was to alter settings in the event of a different attack.
Dawn of the Nth day
BZZT BZZT
Alerting again? Right I'm used to it now. Let's log into cloudflare and see how bad it is this time.
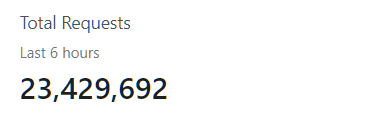
Oh. Well then.
Luckily at this point we'd experienced no downtime. That was about to change. The intensity of the attack rose to around 500,000 per minute, and the dreaded 502 appeared again. This time my NIC wasn't being overwhelmed (thanks cloudflare) and I was able to SSH in and look at the logs.
162.158.234.29 - - [19/Oct/2019:23:47:23 +0100] "GET / HTTP/1.1" 200 439 "-" "Mozilla/5.0 (Amiga; U; AmigaOS 1.3; en; rv:1.8.1.19) Gecko/20081204 SeaMonkey/1.1.14"
162.158.234.121 - - [19/Oct/2019:23:47:23 +0100] "GET / HTTP/1.1" 200 439 "-" "Mozilla/5.0 (Amiga; U; AmigaOS 1.3; en; rv:1.8.1.19) Gecko/20081204 SeaMonkey/1.1.14"
172.69.54.28 - - [19/Oct/2019:23:47:23 +0100] "GET / HTTP/1.1" 200 439 "-" "Mozilla/5.0 (Amiga; U; AmigaOS 1.3; en; rv:1.8.1.19) Gecko/20081204 SeaMonkey/1.1.14"
162.158.234.29 - - [19/Oct/2019:23:47:23 +0100] "GET / HTTP/1.1" 200 439 "-" "Mozilla/5.0 (Amiga; U; AmigaOS 1.3; en; rv:1.8.1.19) Gecko/20081204 SeaMonkey/1.1.14"
141.101.104.96 - - [19/Oct/2019:23:47:23 +0100] "GET / HTTP/1.1" 200 439 "-" "Mozilla/5.0 (Amiga; U; AmigaOS 1.3; en; rv:1.8.1.19) Gecko/20081204 SeaMonkey/1.1.14"
172.69.54.184 - - [19/Oct/2019:23:47:23 +0100] "GET / HTTP/1.1" 200 439 "-" "Mozilla/5.0 (Amiga; U; AmigaOS 1.3; en; rv:1.8.1.19) Gecko/20081204
Luckily there was a commonality in these requests. All were requesting GET /.
Ok sure easy peasy let's just rate limit it. This worked for a while until the attacker
noticed that nothing was happening at which point the request changed to GET /main/public.
Again, just rate limit it. This wasn't 100% effective, because I had to set a minimum number
of requests to the specified URL before the IP would be blocked, and all things considered
this attack consisted of 6000 unique IP addresses, which meant that we were still getting
quite a few requests.
So I looked at my logs again. All participating IPs used a bizarre user agent
of Mozilla/5.0 (Amiga; U; AmigaOS 1.3; en; rv:1.8.1.19) Gecko/20081204 SeaMonkey/1.1.14.
That makes life easier, huh? Just block that and we're good. And good we were.
I apologised to any users that might be using an amiga with an 11-year old Gecko build
and got on with my day.
The attacker then attempted to hurt me by impersonating me on an instance famous for not moderating its content. Ah well. I requested that the admin use the banhammer, and let it be. People know it's not me. This user was thankfully removed.
That is the end of the saga as it stands. I'm pretty sure it's not over yet, but I can't imagine the guy attacking me will carry on for much longer. He has shown borderline-obsessive behaviour towards me which is a bit weird, spending literal weeks trying to target me, but hey, it's only his time he's wasting.
If you're out there reading this, sleepyboi, please take a step back and think about what you are doing. You have gotten kicked off of at least 3 separate cloud providers and have done no more harm than making me watch an episode of yuruyuri to calm myself down in the moment. Which isn't even harm because I mean who doesn't love that stuff?
You clearly have a lot of drive to achieve whatever goal you are aiming for. You could achieve great things if you harnessed that and used it productively.
Night of the Mth day, M > N
I expected that this wasn't over when I finished writing this post initially. I was indeed correct.
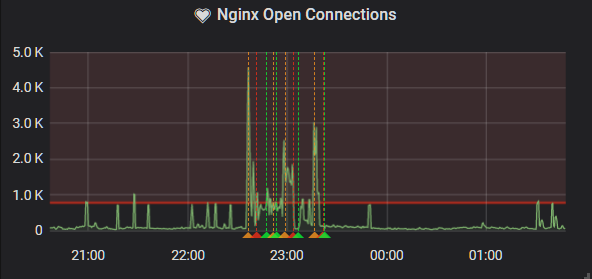
I got the standard alert for nginx open connections, but I didn't worry about it, since usually I could just change a rate limiting rule and it'd fix itself. But this time seemed different. The access logs were coming through differently.
Then this happened:
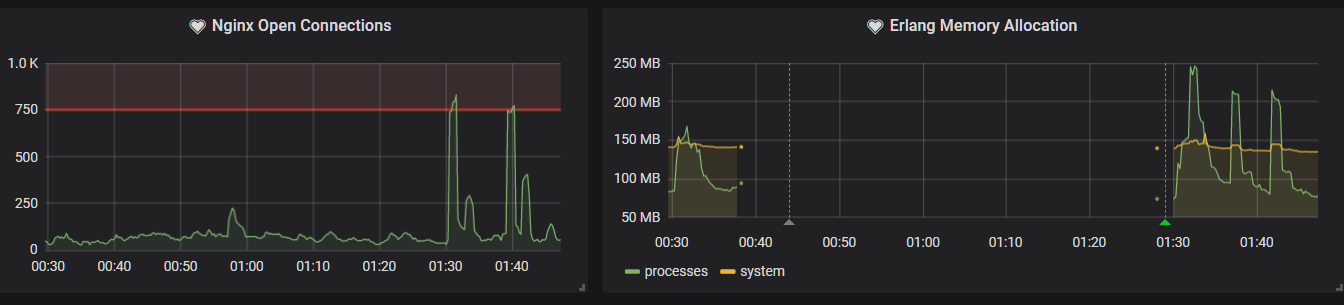
This is a situation I had not seen before. Nginx wasn't showing anything out of the ordinary, yet erlang was dead. I'm still not entirely sure as to the precise nature of this attack, but I am reasonably certain that one of my services was leaking IP information through cloudflare, allowing the attacker to bypass it entirely. I confirmed this by switching IPs a few times, only for the attack to be redirected to me after a few minutes.
The mitigation here was actually quite simple - and is something cloudflare recommend everyone does, yet I hadn't seen. Create a security group that whitelists https traffic from cloudflare origin IPs ONLY, block all other ports to all other IPs.
Once I had done that, we were in the clear again. I still have to investigate from which service my IP leaked.
I won't bother closing the post off again, since I suppose I'll probably be updating this again in the future. I hope I don't have to though.
I spoke with the guy and I hope that he might stop now. I'm not really much of a proper target. Maybe he'll show... some compassion. I have my doubts, but please prove me wrong.
Night of the Pth day, P > M > N
2 attacks today. One I didn't even notice, the other caused a few minutes downtime since i was watching a video. How bad of me, to actually want a relaxing sunday night.
First one was a 7-million request GET / spam at around 20:00. I don't think
anyone noticed this and cloudflare ate it all.
Then at around 00:10 the service went down. tcpdump didn't show anything, so I think scaleway's security groups aren't scalable. My thought is that whatever was leaking my IP is still doing that. Ah well. Swapped IPs, service back up and running.
To think I thought he would stop... I'd be so lucky.
Morning of the P+1th day
The attacker revealed he was getting my backend IP address by posting a controlled image, which was dutifully fetched by pleroma. Ok then. So we're forced to use an upstream proxy.
After much messing, I arrived at this architecture
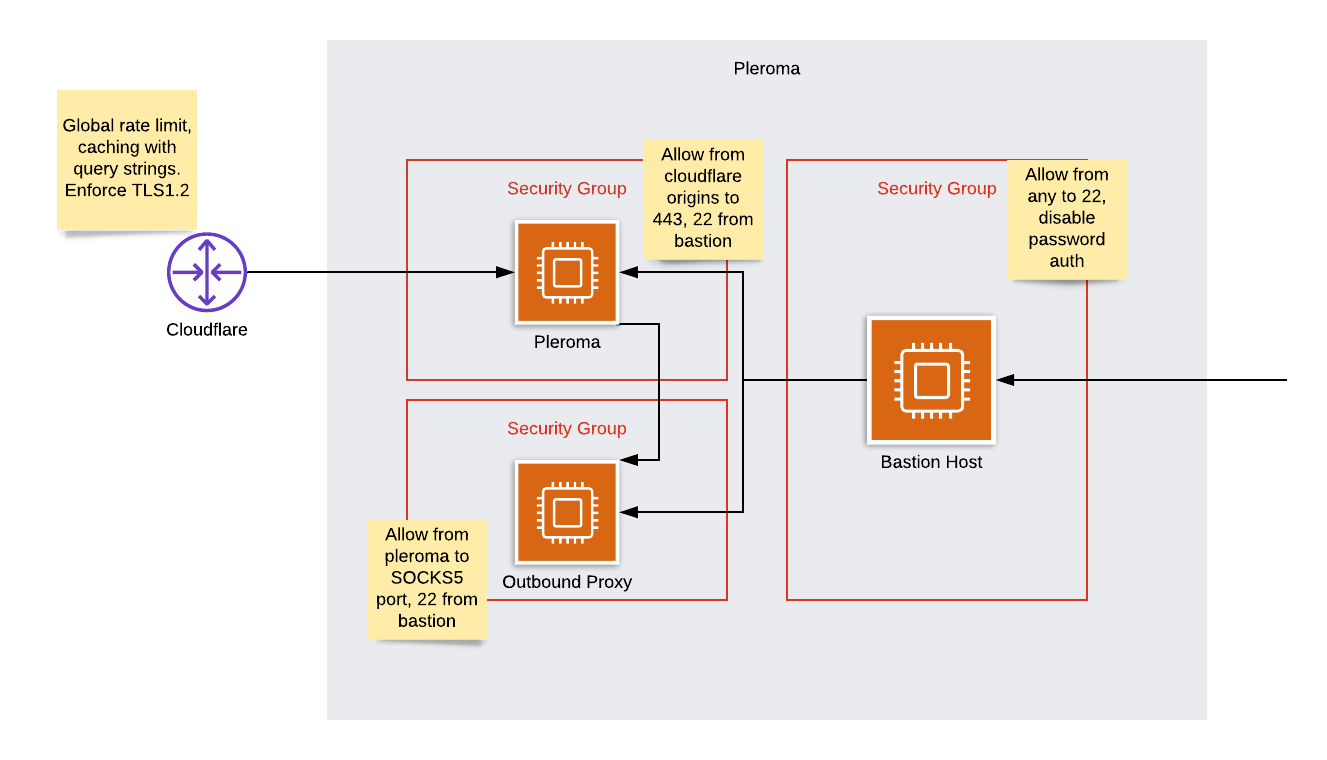
Additional anonymisation steps have been added to make it harder to determine which IP is mine. In the event that my oubound IP is correctly found, the worst impact to service would be delayed outbound federation.
I would advise incredibly strict security groups with as much in the way of rate limiting as you can.
Time will tell if this will suffice.
またね